Sonus-1 reasoning model explained: what changed, what’s real, and what to watch when you deploy it in production.
TL;DR
- Sonus-1 is mostly about making agent behavior predictable and auditable.
- Make tools safe: schemas, validation, retries/timeouts, and idempotency.
- Ground answers with retrieval (RAG) and measure reliability with evals.
- Add observability so you can answer: what happened and why.
Introducing Sonus-1: A High-Performing, FREE Reasoning Model, Rubik’s Sonus 1 model is a free new model that can do reasoning across multiple tasks and beats OpenAI’s new O1 Pro mode for free.
The Sonus-1 family of Large Language Models (LLMs) is designed to be both powerful and versatile, excelling across a range of applications. Sonus-1 is offered to the community completely free, allowing users to leverage cutting-edge AI without cost or restrictions.
Sonus-1 (what it means)
The Sonus-1 Family: Pro, Air, and Mini
The Sonus-1 series is designed to cater to a variety of needs:
- Sonus-1 Mini: Prioritizes speed, offering cost-effective solutions with fast performance.
- Sonus-1 Air: Provides a versatile balance between performance and resource usage.
- Sonus-1 Pro: Is optimized for complex tasks that demand the highest performance levels.
- Sonus-1 Pro (w/ Reasoning): Is the flagship model, enhanced with chain-of-thought reasoning to tackle intricate problems.
Sonus-1 Pro (w/ Reasoning): A Focus on High-Performance Reasoning
The Sonus-1 Pro (w/ Reasoning) model is engineered to excel in challenging tasks requiring sophisticated problem-solving, particularly in reasoning, mathematics, and code.
Benchmark Performance: Sonus-1 Pro Outperforms The Competition
The Sonus-1 family, particularly the Pro model, demonstrates impressive performance across diverse benchmarks. Here’s a detailed breakdown, emphasizing the capabilities of the Sonus-1 Pro (w/ Reasoning) model:
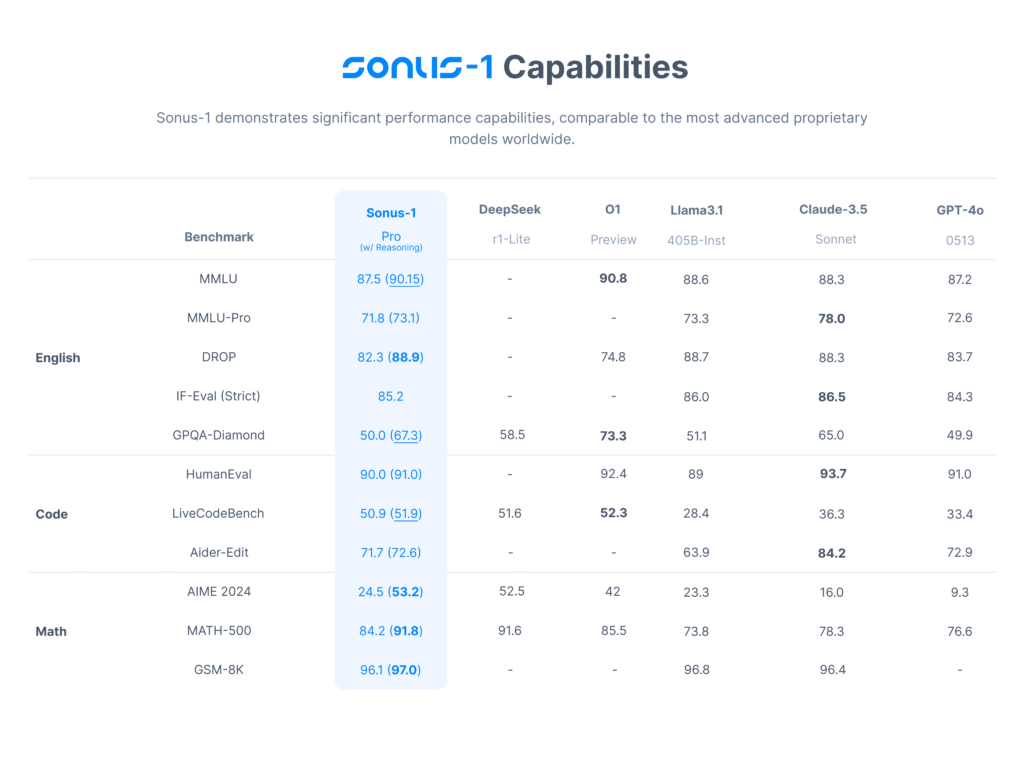
Key Highlights from the Benchmark Data:
- MMLU: The Sonus-1 Pro (w/ Reasoning) model achieves 90.15% demonstrating its powerful general reasoning capabilities.
- MMLU-Pro: Achieves 73.1%, highlighting its robust capabilities for more complex reasoning problems.
- Math (MATH-500): With a score of 91.8%, Sonus-1 Pro (w/ Reasoning) proves its prowess in handling intricate mathematical problems.
- Reasoning (DROP): Achieves 88.9%, demonstrating its strong capabilities in reasoning tasks.
- Reasoning (GPQA-Diamond): Achieves 67.3% on the challenging GPQA-Diamond, highlighting its ability in scientific reasoning.
- Code (HumanEval): Scores 91.0%, showcasing its strong coding abilities.
- Code (LiveCodeBench): Achieves 51.9%, displaying impressive performance in real-world code environments.
- Math (GSM-8k): Achieves an impressive 97% on the challenging GSM-8k math test.
- Code (Aider-Edit): Demonstrates solid performance in code editing by achieving 72.6%.
Sonus-1 Pro excels in various benchmarks, and stands out in reasoning and mathematical tasks, often surpassing the performance of other proprietary models.
Where to Try Sonus-1?
The Sonus-1 suite of models can be explored at chat.sonus.ai. Users are encouraged to test the models and experience their performance firsthand.
What’s Next?
The development of high-performance, reliable, and privacy-focused LLMs is ongoing, with future releases planned to tackle even more complex problems.
Try Sonus-1 Demo Here: https://chat.sonus.ai/sonus

Leave a Reply