-
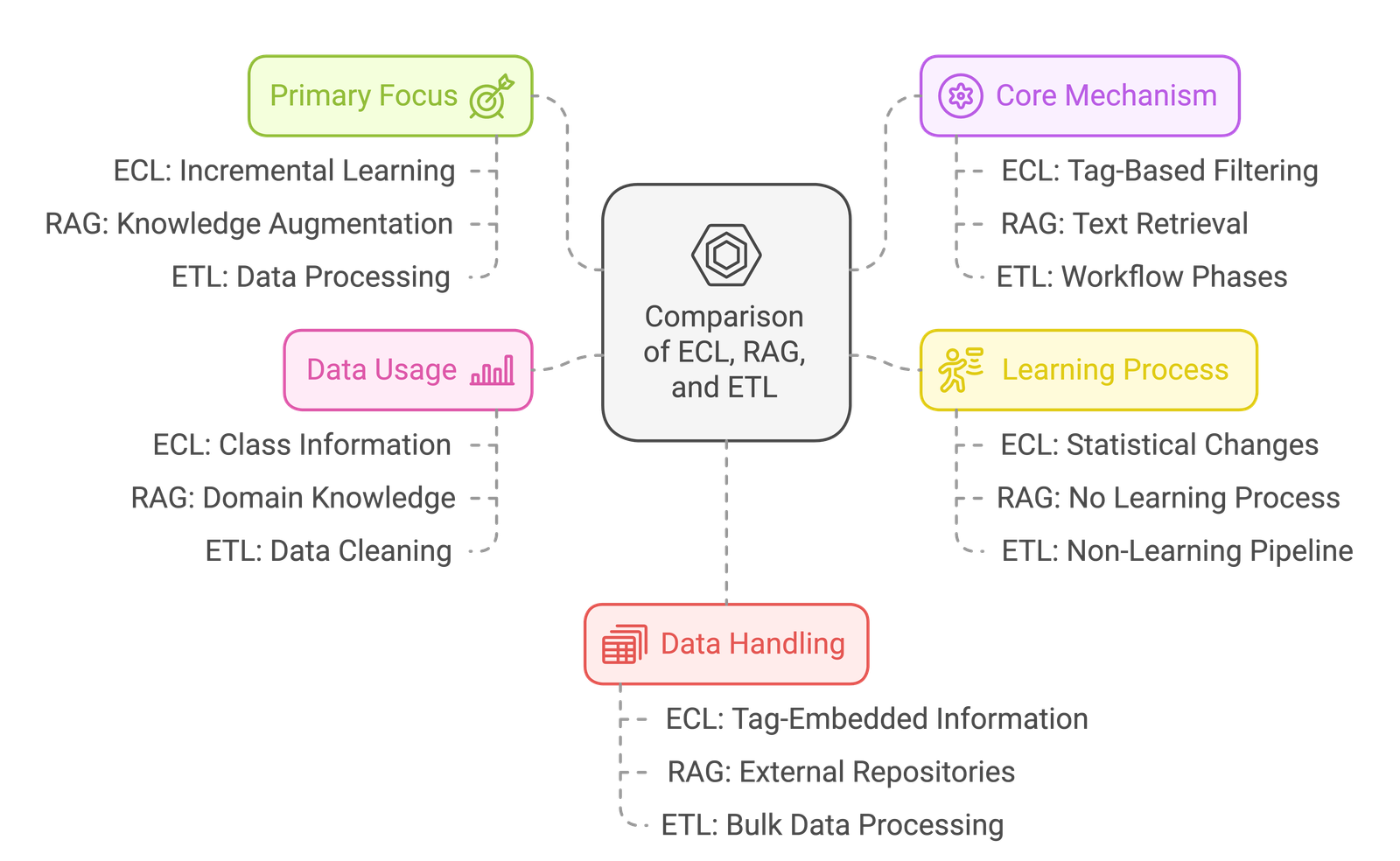
ECL vs RAG, What is ETL: AI Learning, Data, and Transformation
TL;DR Ecl Vs Rag is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with…