-
Simile Raises $100M to Simulate Human Behavior — Why This Could Be the Missing Layer for AI Agents
Simile $100M human behavior simulation is one of the most interesting “infrastructure bets” in the agent era. Joon Sung Park introduced Simile as a platform for simulating human behavior, and…
-
What Are Tokens in NLP?
What Are Tokens is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-
What is Infinite Retrieval, and How Does It Work?
TL;DR Infinite Retrieval is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-

Understanding LLM Parameters: A Comprehensive Guide
TL;DR Llm Parameters is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-
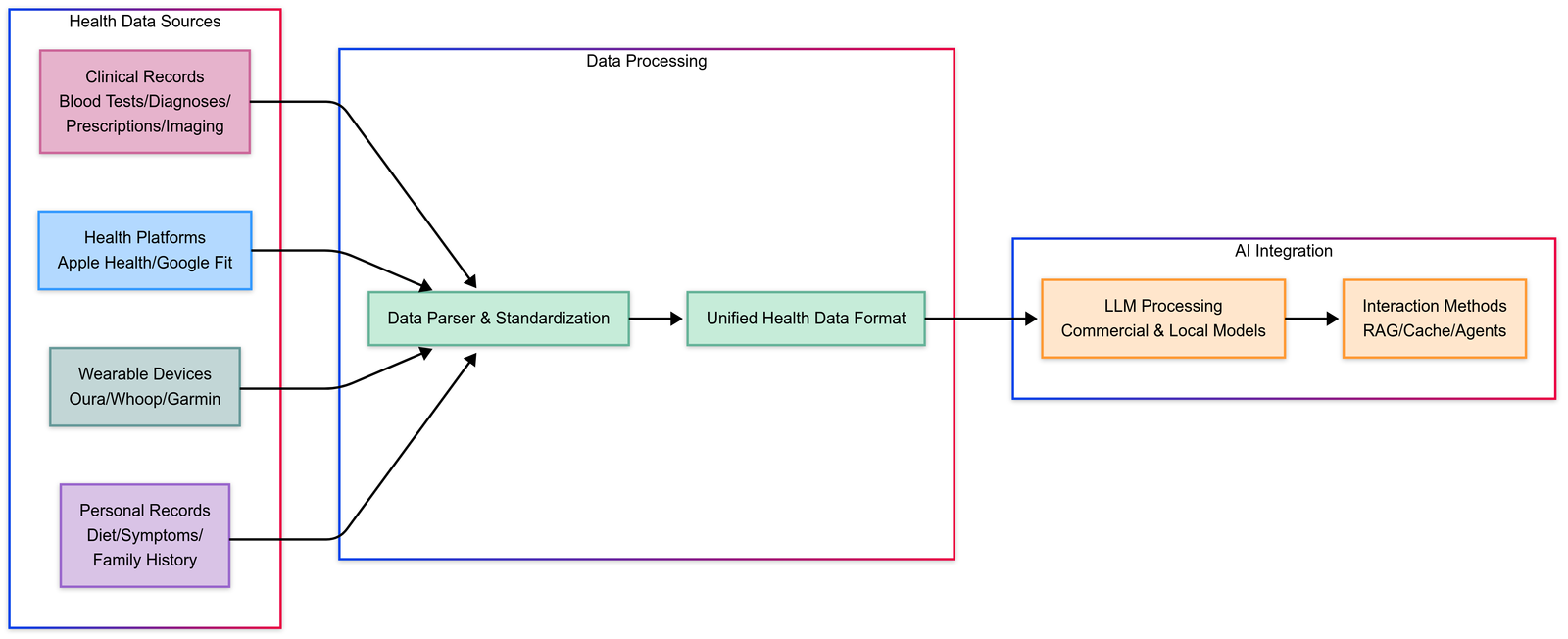
Build Your Own and Free AI Health Assistant, Personalized Healthcare
TL;DR Build Your Own Free is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability…
-

How to Install and Run Virtuoso-Medium-v2 Locally: A Step-by-Step Guide
TL;DR Virtuoso-Medium-V2 is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…
-

DeepSeek Shakes the AI World—How Qwen2.5-Max Change the Game
TL;DR Qwen2.5-Max is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…
-
Qwen2.5-Max: Alibaba’s New AI Model Outperforms DeepSeek, GPT-4o, and Claude Sonnet
TL;DR Qwen2.5-Max is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…
-
Deploy an uncensored DeepSeek R1 model on Google Cloud Run
TL;DR Deploy Uncensored Deepseek Model is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with…