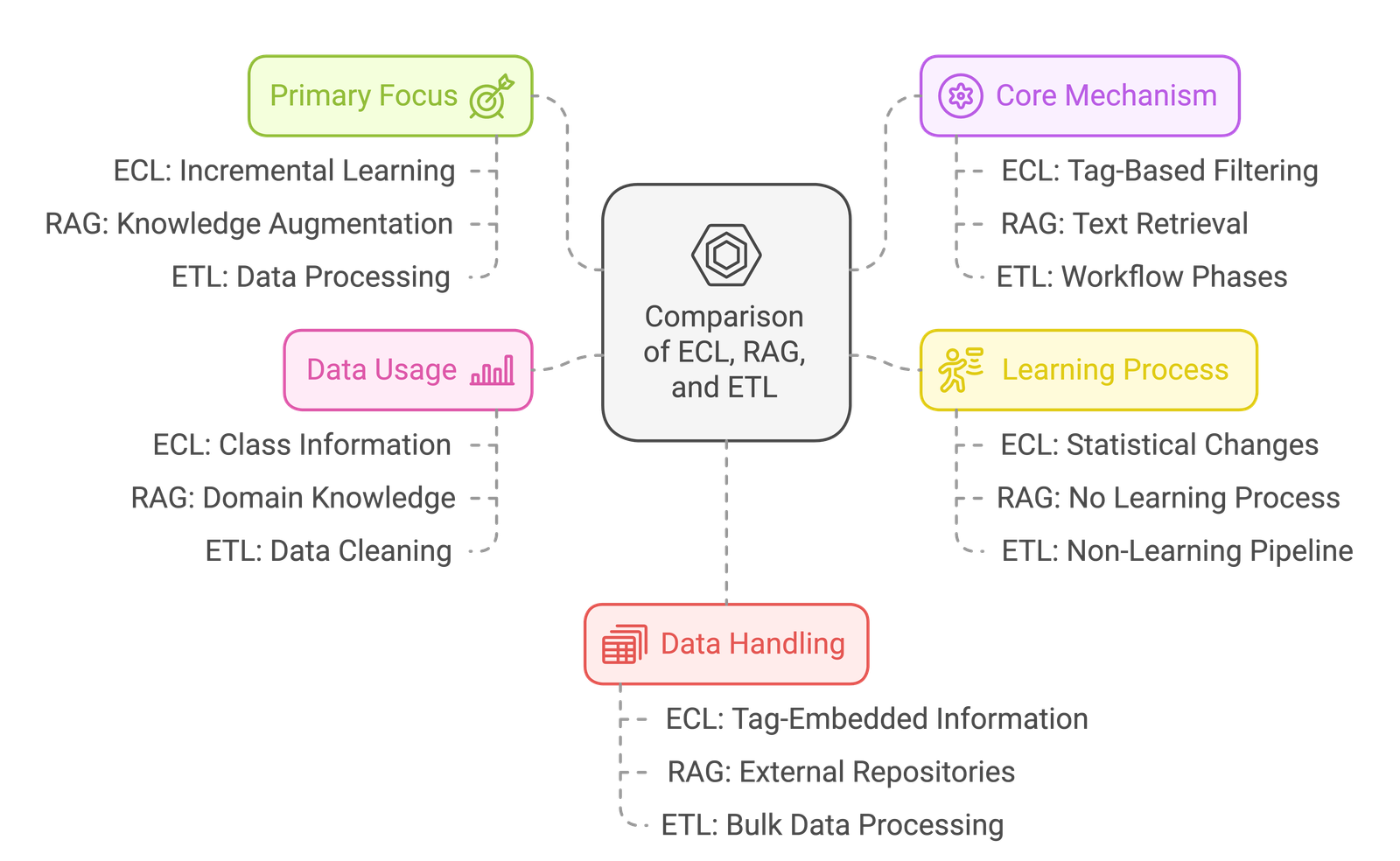
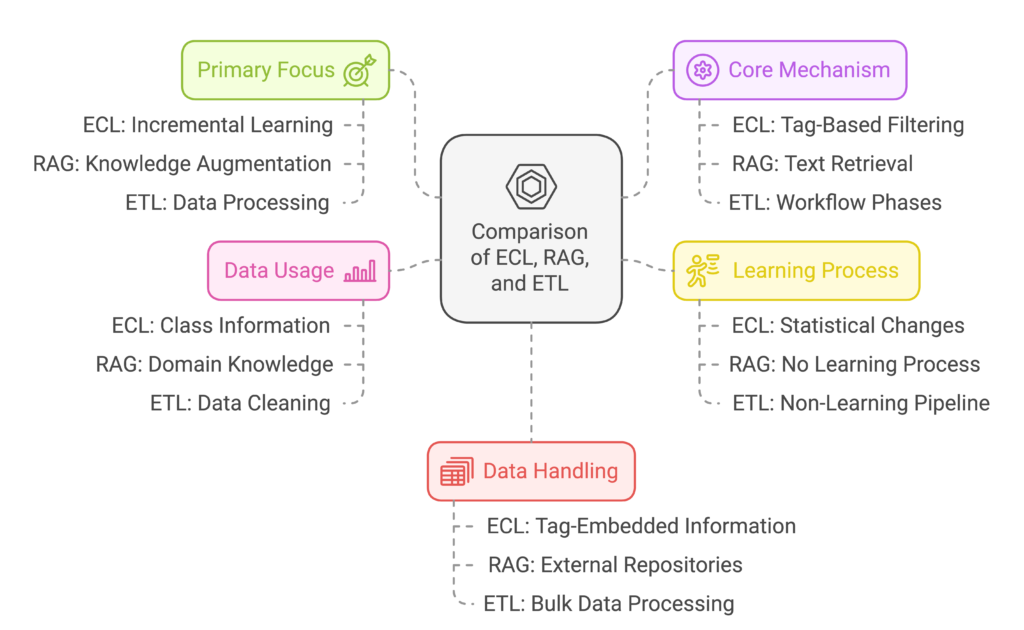
What is NVIDIA NV Ingest?
NVIDIA NV Ingest is not a static pipeline; it’s a dynamic microservice designed for processing various document formats, including PDF, DOCX, and PPTX. It uses NVIDIA NIM microservices to identify, extract, and contextualize information, such as text, tables, charts, and images. The core aim is to transform unstructured data into structured metadata and text, facilitating its use in downstream applications
At its core, NVIDIA NV Ingest is a performance-oriented, scalable microservice designed for document content and metadata extraction. Leveraging specialized NVIDIA NIM microservices, this tool goes beyond simple text extraction. It intelligently identifies, contextualizes, and extracts text, tables, charts, and images from a variety of document formats, including PDFs, Word, and PowerPoint files. This enables a streamlined workflow for feeding data into downstream generative AI applications, such as retrieval-augmented generation (RAG) systems.
NVIDIA Ingest works by accepting a JSON job description, outlining the document payload and the desired ingestion tasks. The result is a JSON dictionary containing a wealth of metadata about the extracted objects and associated processing details. It’s crucial to note that NVIDIA Ingest doesn’t simply act as a wrapper around existing parsing libraries; rather, it’s a flexible and adaptable system that is designed to manage complex document processing workflows.
Key Capabilities
Here’s what NVIDIA NV Ingest is capable of:
- Multi-Format Support: Handles a variety of documents, including PDF, DOCX, PPTX, and image formats.
- Versatile Extraction Methods: Offers multiple extraction methods per document type, balancing throughput and accuracy. For PDFs, you can leverage options like pdfium, Unstructured.io, and Adobe Content Extraction Services.
- Advanced Pre- and Post-Processing: Supports text splitting, chunking, filtering, embedding generation, and image offloading.
- Parallel Processing: Enables parallel document splitting, content classification (tables, charts, images, text), extraction, and contextualization via Optical Character Recognition (OCR).
- Vector Database Integration: NVIDIA Ingest also manages the computation of embeddings and can optionally store these into vector database like Milvus
Why NVIDIA NV Ingest?
Unlike static pipelines, NVIDIA Ingest provides a flexible framework. It is not a wrapper for any specific parsing library. Instead, it orchestrates the document processing workflow based on your job description.
The need to parse hundreds of thousands of complex, messy unstructured PDFs is often a major hurdle. NVIDIA Ingest is designed for exactly this scenario, providing a robust and scalable system for large-scale data processing. It breaks down complex PDFs into discrete content, contextualizes it through OCR, and outputs a structured JSON schema which is very easy to use for AI applications.
Getting Started with NVIDIA NV Ingest
To get started, you’ll need:
- Hardware: NVIDIA GPUs (H100 or A100 with at least 80GB of memory, with minimum of 2 GPUs)
Software
- Operating System: Linux (Ubuntu 22.04 or later is recommended)
- Docker: For containerizing and managing microservices
- Docker Compose: For multi-container application deployment
- CUDA Toolkit: (NVIDIA Driver >= 535, CUDA >= 12.2)
- NVIDIA Container Toolkit: For running NVIDIA GPU-accelerated containers
- NVIDIA API Key: Required for accessing pre-built containers from NVIDIA NGC. To get early access for NVIDIA Ingest https://developer.nvidia.com/nemo-microservices-early-access/join
Step-by-Step Setup and Usage
1. Starting NVIDIA NIM Microservices Containers
- Clone the repository:
git clonehttps://github.com/nvidia/nv-ingestcd nv-ingest - Log in to NVIDIA GPU Cloud (NGC):
docker login nvcr.io# Username: $oauthtoken# Password: <Your API Key> - Create a .env file:
Add your NGC API key and any other required paths:NGC_API_KEY=your_api_key NVIDIA_BUILD_API_KEY=optional_build_api_key - Start the containers:
sudo nvidia-ctk runtime configure --runtime=docker --set-as-defaultdocker compose up
Note: NIM containers might take 10-15 minutes to fully load models on first startup.
2. Installing Python Client Dependencies
- Create a Python environment (optional but recommended):
conda create --name nv-ingest-dev --file ./conda/environments/nv_ingest_environment.ymlconda activate nv-ingest-dev - Install the client:
cd clientpip install .
if you are not using conda you can install directly
#pip install -r requirements.txt
#pip install .
“`
Note: You can perform these steps from your host machine or within the nv-ingest container.
3. Submitting Ingestion Jobs
Python Client Example:
import logging, time
from nv_ingest_client.client import NvIngestClient
from nv_ingest_client.primitives import JobSpec
from nv_ingest_client.primitives.tasks import ExtractTask
from nv_ingest_client.util.file_processing.extract import extract_file_content
logger = logging.getLogger("nv_ingest_client")
file_name = "data/multimodal_test.pdf"
file_content, file_type = extract_file_content(file_name)
job_spec = JobSpec(
document_type=file_type,
payload=file_content,
source_id=file_name,
source_name=file_name,
extended_options={
"tracing_options": {
"trace": True,
"ts_send": time.time_ns()
}
}
)
extract_task = ExtractTask(
document_type=file_type,
extract_text=True,
extract_images=True,
extract_tables=True
)
job_spec.add_task(extract_task)
client = NvIngestClient(
message_client_hostname="localhost", # Host where nv-ingest-ms-runtime is running
message_client_port=7670 # REST port, defaults to 7670
)
job_id = client.add_job(job_spec)
client.submit_job(job_id, "morpheus_task_queue")
result = client.fetch_job_result(job_id, timeout=60)
print(f"Got {len(result)} results")Command Line (nv-ingest-cli) Example:
nv-ingest-cli \
--doc ./data/multimodal_test.pdf \
--output_directory ./processed_docs \
--task='extract:{"document_type": "pdf", "extract_method": "pdfium", "extract_tables": "true", "extract_images": "true"}' \
--client_host=localhost \
--client_port=7670Note: Make sure to adjust the file_path, client_host and client_port as per your setup.
Note: extract_tables controls both table and chart extraction, you can disable chart extraction using extract_charts parameter set to false.
4. Inspecting Results
Post ingestion, results can be found in processed_docs directory, under text, image and structured subdirectories. Each result will contain corresponding json metadata files. You can inspect the extracted images using the provided image viewer script:
- First, install
tkinterby running the following commands depending on your OS.For Ubuntu/Debian:sudo apt-get updatesudo apt-get install python3-tk# For Fedora/RHEL:sudo dnf install python3-tkinter# For MacOSbrew install python-tk - Run image viewer:
python src/util/image_viewer.py --file_path ./processed_docs/image/multimodal_test.pdf.metadata.json
Understanding the Output
The output of NVIDIA NV Ingest is a structured JSON document, which contains:
- Extracted Text: Text content from the document.
- Extracted Tables: Table data in structured format.
- Extracted Charts: Information about charts present in the document.
- Extracted Images: Metadata for extracted images.
- Processing Annotations: Timing and tracing data for analysis.
This output can be easily integrated into various systems, including vector databases for semantic search and LLM applications.
This output can be easily integrated into various systems, including vector databases for semantic search and LLM applications.
NVIDIA NV Ingest Use Cases
NVIDIA NV Ingest is ideal for various applications, including:
- Retrieval-Augmented Generation (RAG): Enhance LLMs with accurate and contextualized data from your documents.
- Enterprise Search: Improve search capabilities by indexing text and metadata from large document repositories.
- Data Analysis: Unlock hidden patterns and insights within unstructured data.
- Automated Document Processing: Streamline workflows by automating the extraction process from unstructured documents.
Troubleshooting
Common Issues
- NIM Containers Not Starting: Check resource availability (GPU memory, CPU), verify NGC login details, and ensure the correct CUDA driver is installed.
- Python Client Errors: Verify dependencies are installed correctly and the client is configured to connect with the running service.
- Job Failures: Examine the logs for detailed error messages, check the input document for errors, and verify task configuration.
Tips
- Verbose Logging: Enable verbose logging by setting NIM_TRITON_LOG_VERBOSE=1 in docker-compose.yaml to help diagnose issues.
- Container Logs: Use docker logs to inspect logs for each container to identify problems.
- GPU Utilization: Use nvidia-smi to monitor GPU activity. If it takes more than a minute for nvidia-smi command to return there is a high chance that the GPU is busy setting up the models.