-
What is Infinite Retrieval, and How Does It Work?
TL;DR Infinite Retrieval is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-

Microsoft’s Majorana 1 chip: Microsoft’s Path to a Fault-Tolerant Future?
TL;DR Microsoft’S Majorana 1 Chip is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability…
-

Understanding LLM Parameters: A Comprehensive Guide
TL;DR Llm Parameters is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-

Never Start From Scratch: Persistent Browser Sessions for AI Agents
TL;DR Persistent Browser Session For Ai is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure…
-

Mastering Scalability: Custom Blockchain Solutions for Enterprise-Level Applications
TL;DR Mastering Scalability is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals.…
-
Unichain: DeFi on Ethereum L2 – Everything You Need to Know
TL;DR Unichain is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…
-

2025: Best and free platform to deploy python application like vercel
TL;DR Deploy Python Application Free is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability…
-
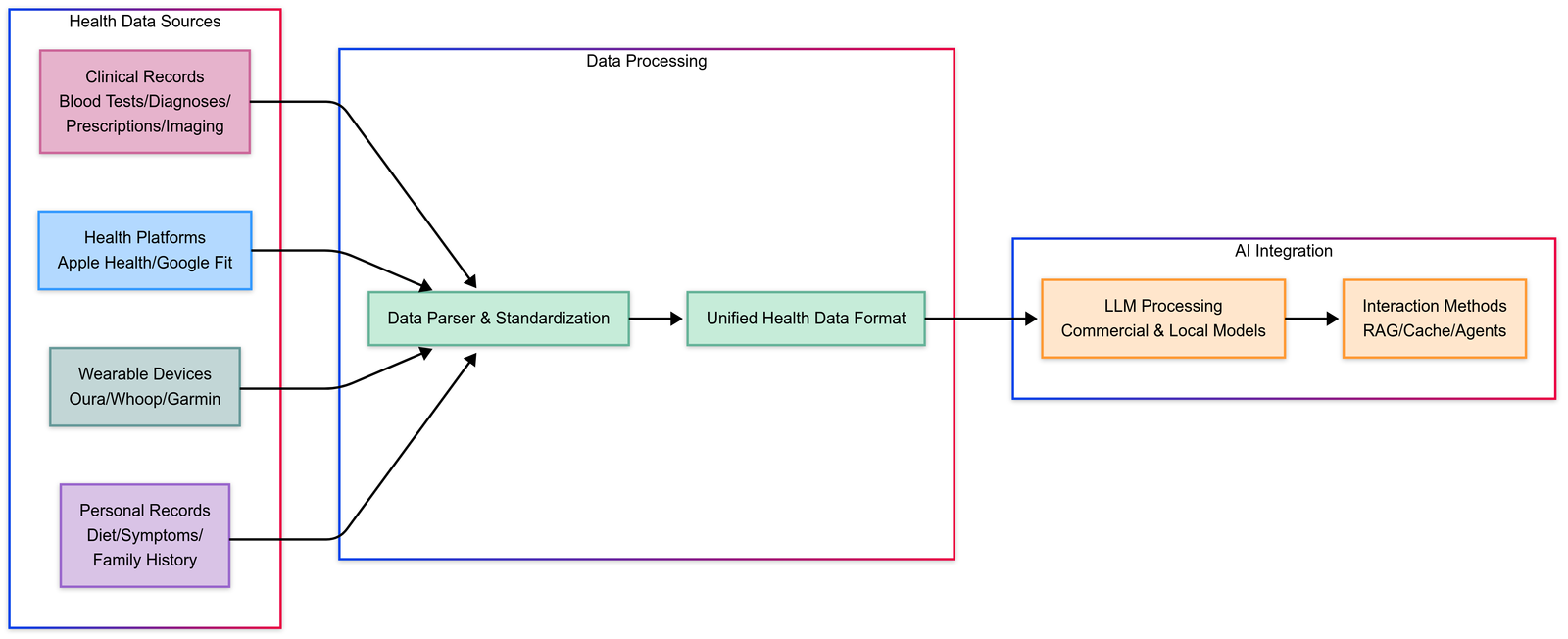
Build Your Own and Free AI Health Assistant, Personalized Healthcare
TL;DR Build Your Own Free is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability…
-
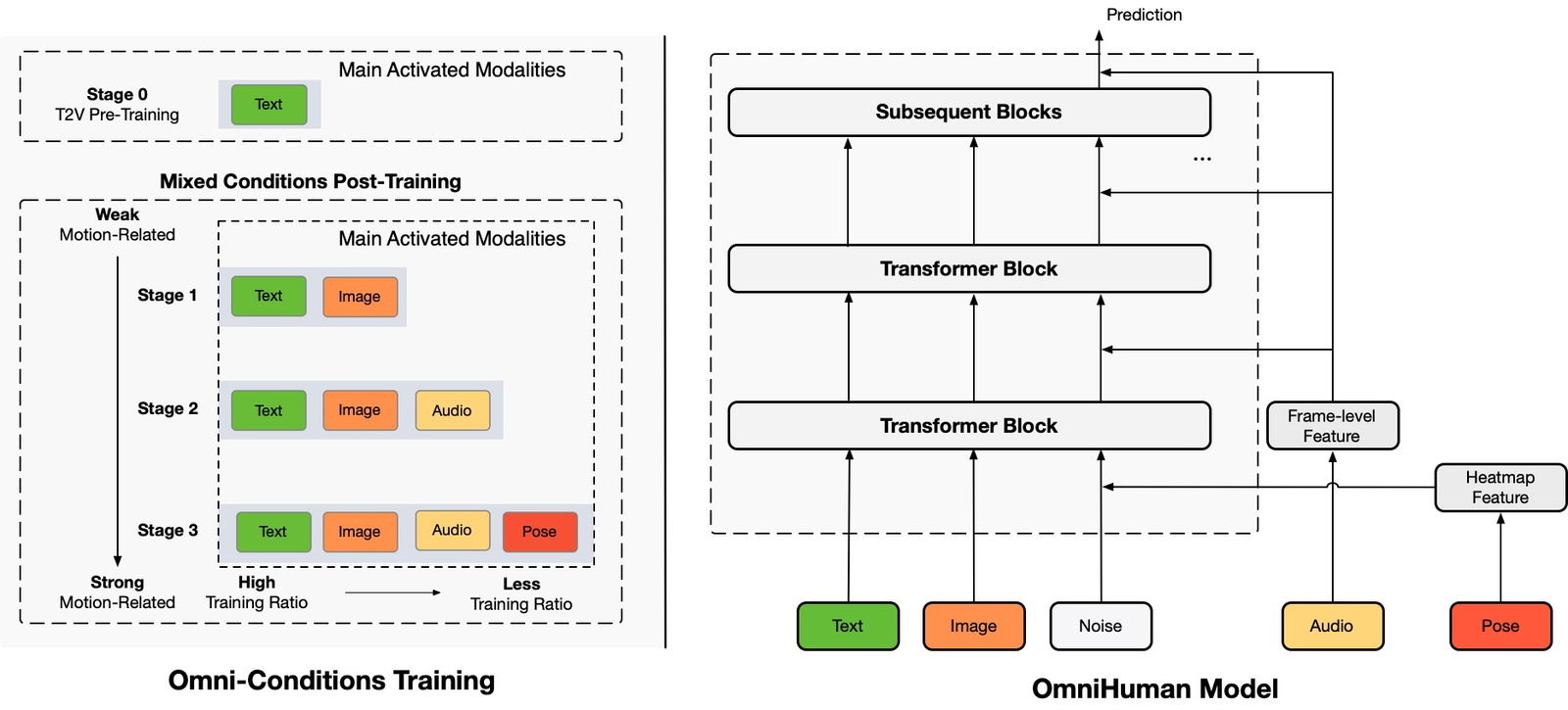
OmniHuman-1: AI Model Generates Lifelike Human Videos from a Single Image
TL;DR Omnihuman is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…
-

How to Install and Run Virtuoso-Medium-v2 Locally: A Step-by-Step Guide
TL;DR Virtuoso-Medium-V2 is mostly about making agent behavior predictable and auditable. Make tools safe: schemas, validation, retries/timeouts, and idempotency. Ground answers with retrieval (RAG) and measure reliability with evals. Add…