-
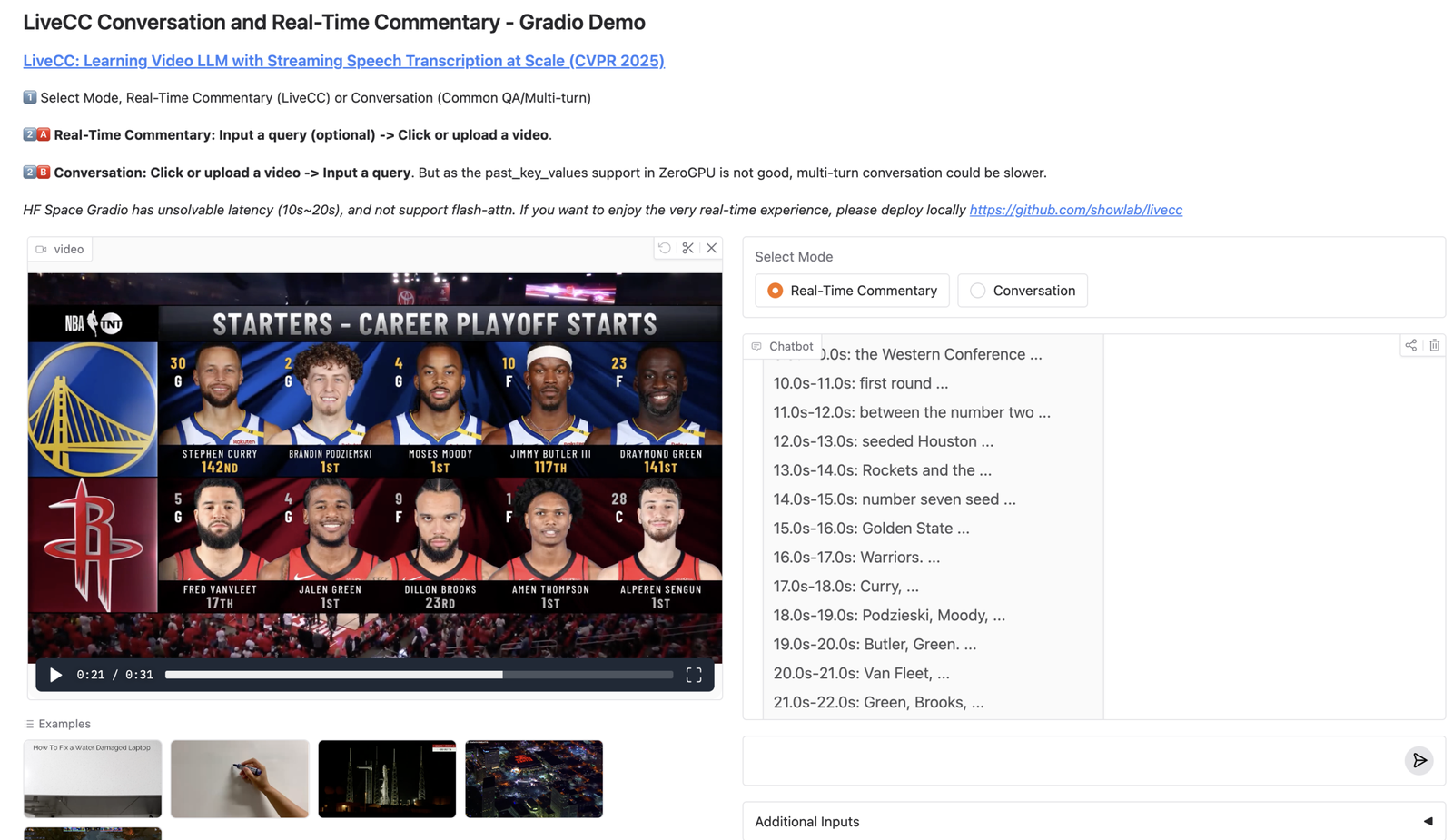
Video LLM for Real-Time Commentary with Streaming Speech Transcription | LiveCC
LiveCC video LLM is an open-source project that trains a video LLM to generate real-time commentary while the video is still playing, by pairing video understanding with streaming speech transcription.…
-

Routing Traces, Metrics, and Logs for LLM Agents (Pipelines + Exporters) | OpenTelemetry Collector
OpenTelemetry Collector for LLM agents: The OpenTelemetry Collector is the most underrated piece of an LLM agent observability stack. Instrumenting your agent runtime is step 1. Step 2 (the step…
-

Lightweight Distributed Tracing for Agent Workflows (Quick Setup + Visibility) | Zipkin
Zipkin for LLM agents: Zipkin is the “get tracing working today” option. It’s lightweight, approachable, and perfect when you want quick visibility into service latency and failures without adopting a…
-

Storing High-Volume Agent Traces Cost-Efficiently (OTel/Jaeger/Zipkin Ingest) | Grafana Tempo
Grafana Tempo for LLM agents: Grafana Tempo is built for one job: store a huge amount of tracing data cheaply, with minimal operational complexity. That matters for LLM agents because…
-

Debugging LLM Agent Tool Calls with Distributed Traces (Run IDs, Spans, Failures) | Jaeger
Jaeger for LLM agents: Jaeger is one of the easiest ways to see what your LLM agent actually did in production. When an agent fails, the final answer rarely tells…
-
LLM Agent Tracing & Distributed Context: End-to-End Spans for Tool Calls + RAG | OpenTelemetry (OTel)
OpenTelemetry (OTel) is the fastest path to production-grade tracing for LLM agents because it gives you a standard way to follow a request across your agent runtime, tools, and downstream…
-
LLM Agent Observability & Audit Logs: Tracing, Tool Calls, and Compliance (Enterprise Guide)
Enterprise LLM agents don’t fail like normal software. They fail in ways that look random: a tool call that “usually works” suddenly breaks, a prompt change triggers a new behavior,…
-
Tool Calling Reliability for LLM Agents: Schemas, Validation, Retries (Production Checklist)
Tool calling is where most “agent demos” die in production. Models are great at writing plausible text, but tools require correct structure, correct arguments, and correct sequencing under timeouts, partial…
-
Agent Evaluation Framework: How to Test LLM Agents (Offline Evals + Production Monitoring)
If you ship LLM agents in production, you’ll eventually hit the same painful truth: agents don’t fail once-they fail in new, surprising ways every time you change a prompt, tool,…
-
OpenAI CoVal Dataset: What It Is and How to Use Values-Based Evaluation
OpenAI CoVal dataset (short for crowd-originated, values-aware rubrics) is one of the most practical alignment releases in a while because it tries to capture something preference datasets usually miss: why…